

ELEC-TDNN: electromagnetic fingerprint recognition based on neural network
-
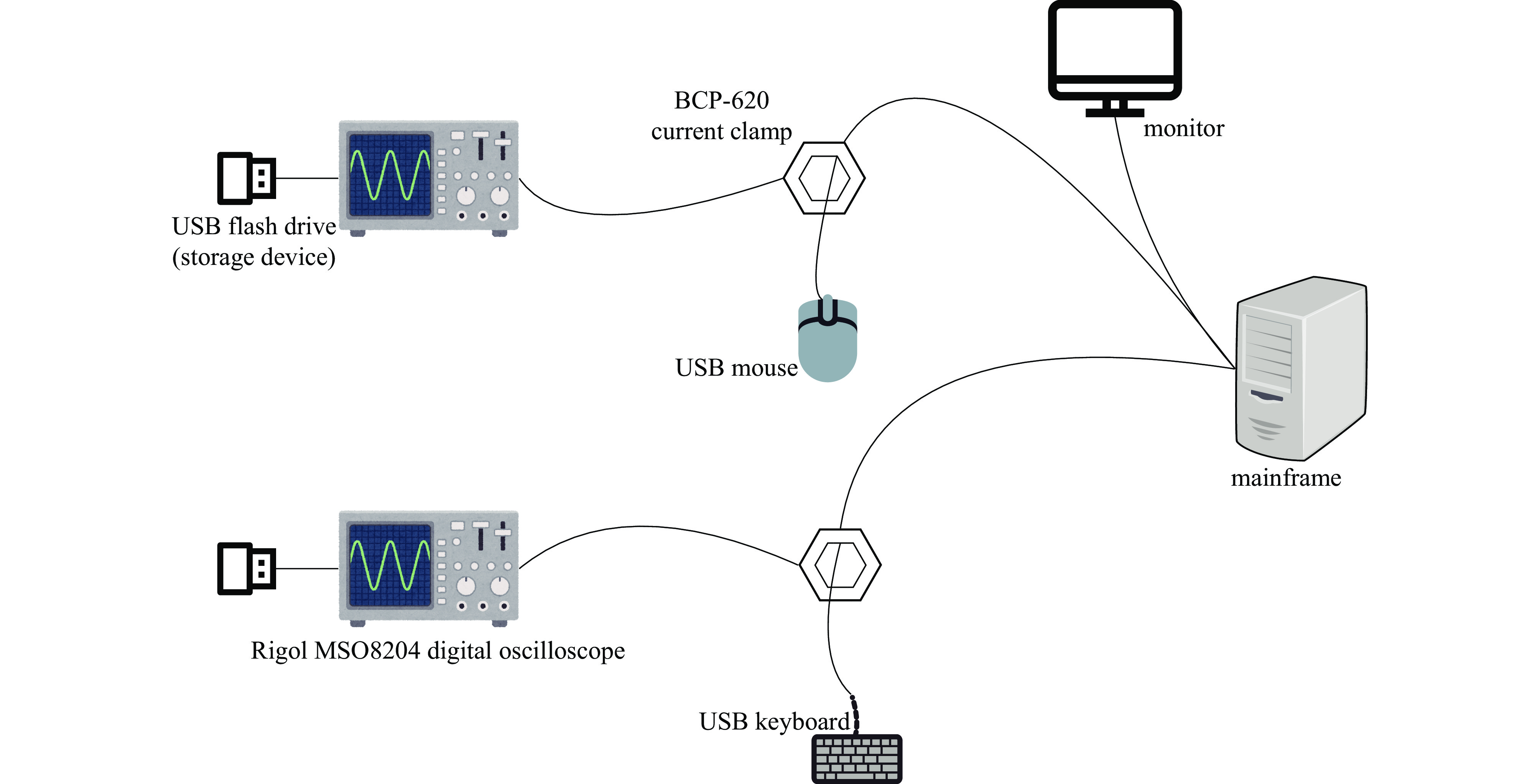
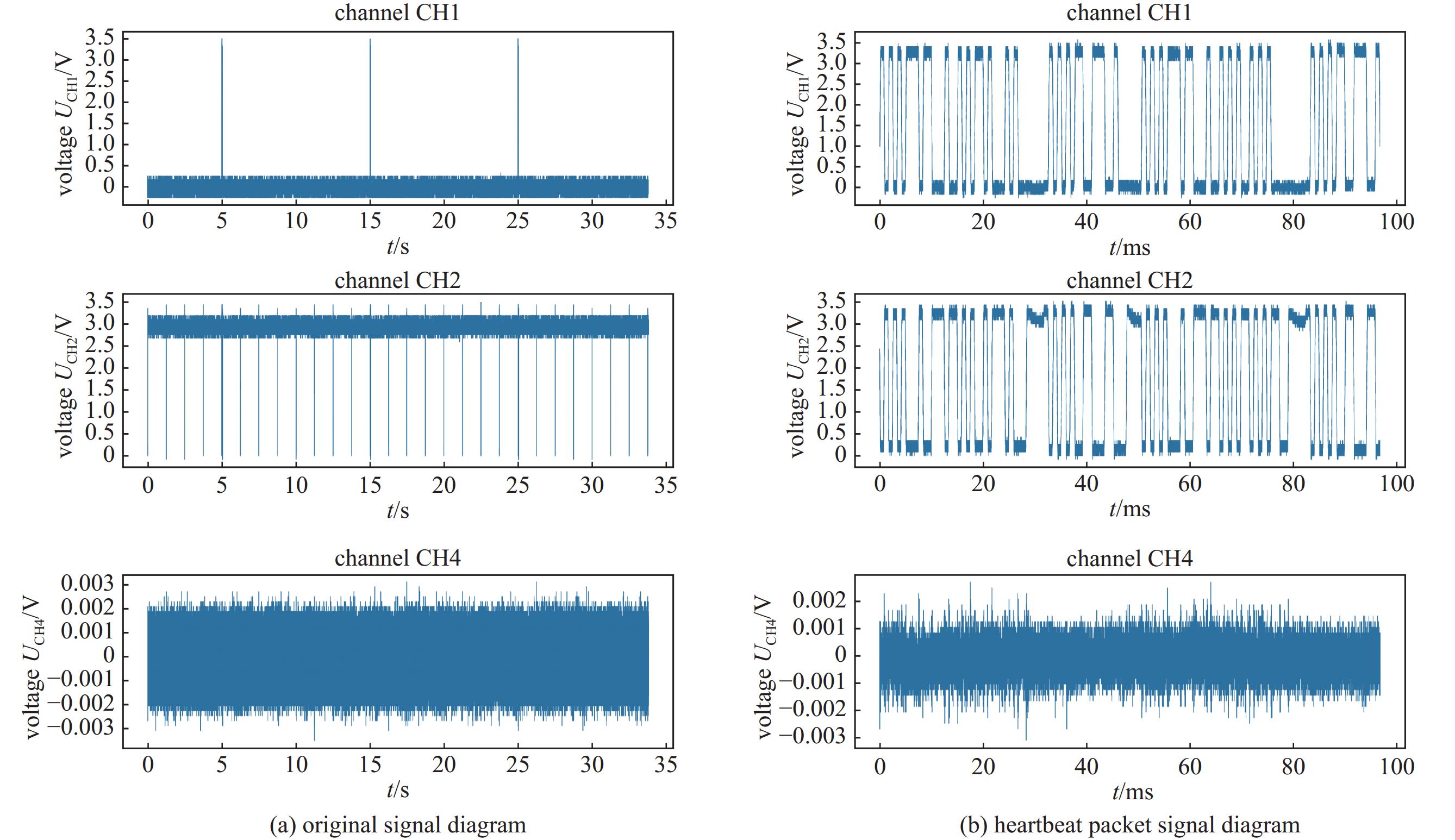
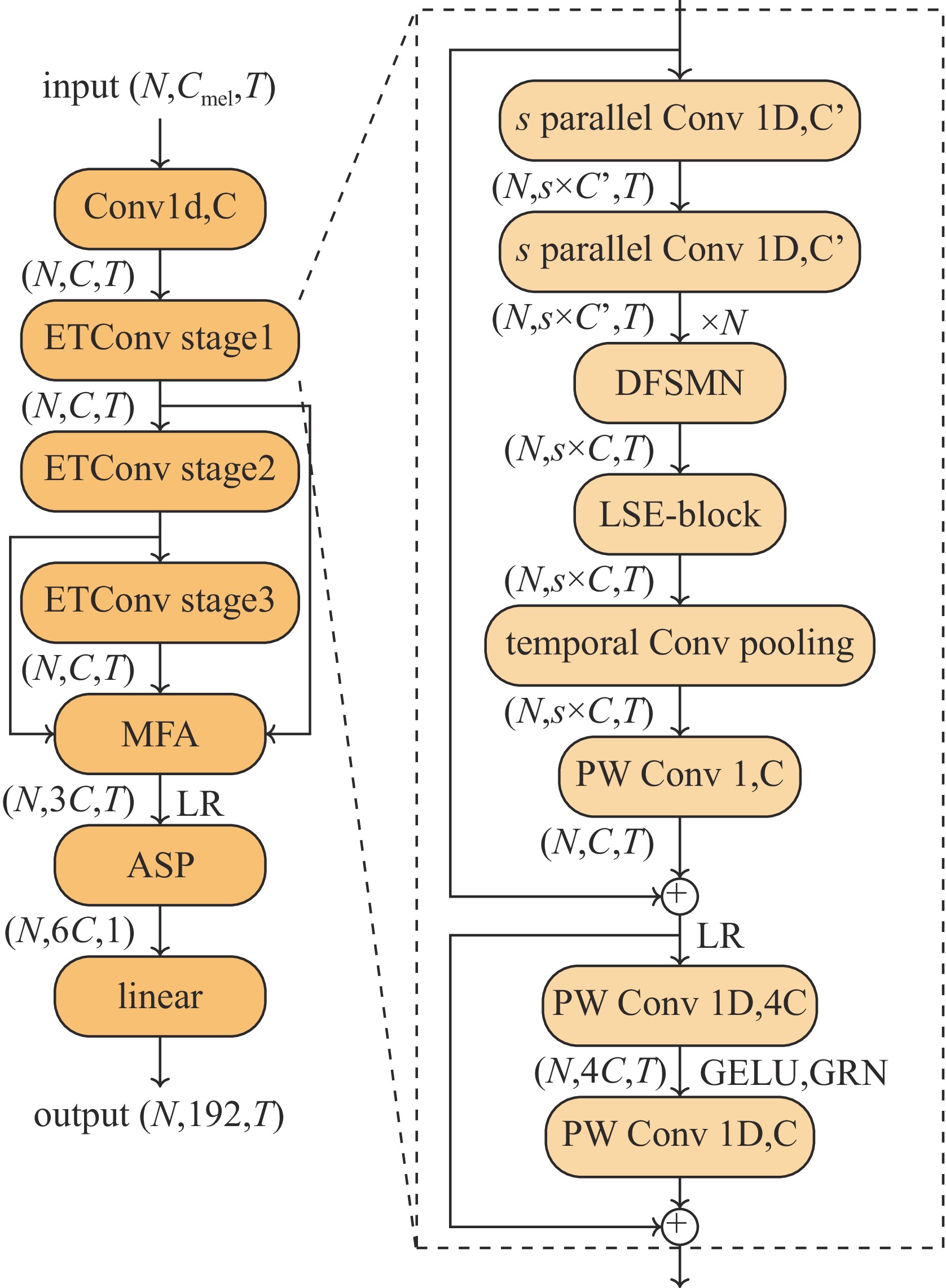
摘要: 电子设备在运行过程中产生的电磁辐射可能导致信息泄漏,对信息安全构成威胁。电磁指纹识别方法在安全检测和漏源定位中发挥着重要作用。电磁指纹识别在实际检测中需要准确性和适应性,现有电磁指纹识别方法存在跨采样率适配性差、高频特征提取不足等缺陷。为此提出增强型神经网络架构ELEC-TDNN,模型融合了通道注意力机制与多尺度时序建模能力,设计引入局部信号增强层等模块,并基于自建双采样率(1.25 GHz/500 MHz)的USB设备电磁辐射数据集进行了实验。实验结果表明,ELEC-TDNN具有较高的精度,能够适应不同的采样率。在500 MHz采样率下,模型等错误率最低可达0.35%,在1.25 GHz高频场景下,等错误率为5.23%。Abstract:
Background Electromagnetic (EM) emissions from electronic devices can inadvertently carry sensitive information, posing significant threats to information security. EM fingerprinting techniques have become vital for security inspection and leakage source localization, yet existing approaches often suffer from poor adaptability across sampling rates and insufficient extraction of high-frequency features.Purpose This study aims to develop a robust EM fingerprint recognition method that maintains high accuracy across different sampling rates while effectively capturing high-frequency characteristics, thereby improving security detection and adaptability in practical scenarios.Methods We propose an enhanced neural network architecture, termed ELEC-TDNN, which integrates a channel attention mechanism with multi-scale temporal modeling capabilities. A local signal enhancement layer is introduced to improve the representation of subtle EM features. Experiments were conducted on a self-constructed dual-sampling-rate USB device EM emission dataset (1.25 GHz and 500 MHz) to evaluate performance. The evaluation used equal error rate (EER) as the primary metric to measure recognition accuracy under varying frequency conditions.Results The proposed ELEC-TDNN achieved superior adaptability and accuracy compared with conventional methods. At 500 MHz, the model attained a minimum EER of 0.35%, while in the high-frequency 1.25 GHz scenario, it achieved an EER of 5.23%. These results indicate that the architecture effectively preserves recognition performance despite significant differences in sampling rates.Conclusions By combining attention-based channel feature selection, multi-scale temporal modeling, and local signal enhancement, the method addresses both cross-sampling-rate adaptability and high-frequency feature extraction challenges. This work demonstrates practical value in enhancing EM security detection systems and offers a scalable approach for future EM analysis in multi-rate environments. -
表 1 不同模型在USB设备辐射信号数据集上的实验结果
Table 1. Experimental results of different models on the radiation signal dataset of USB devices
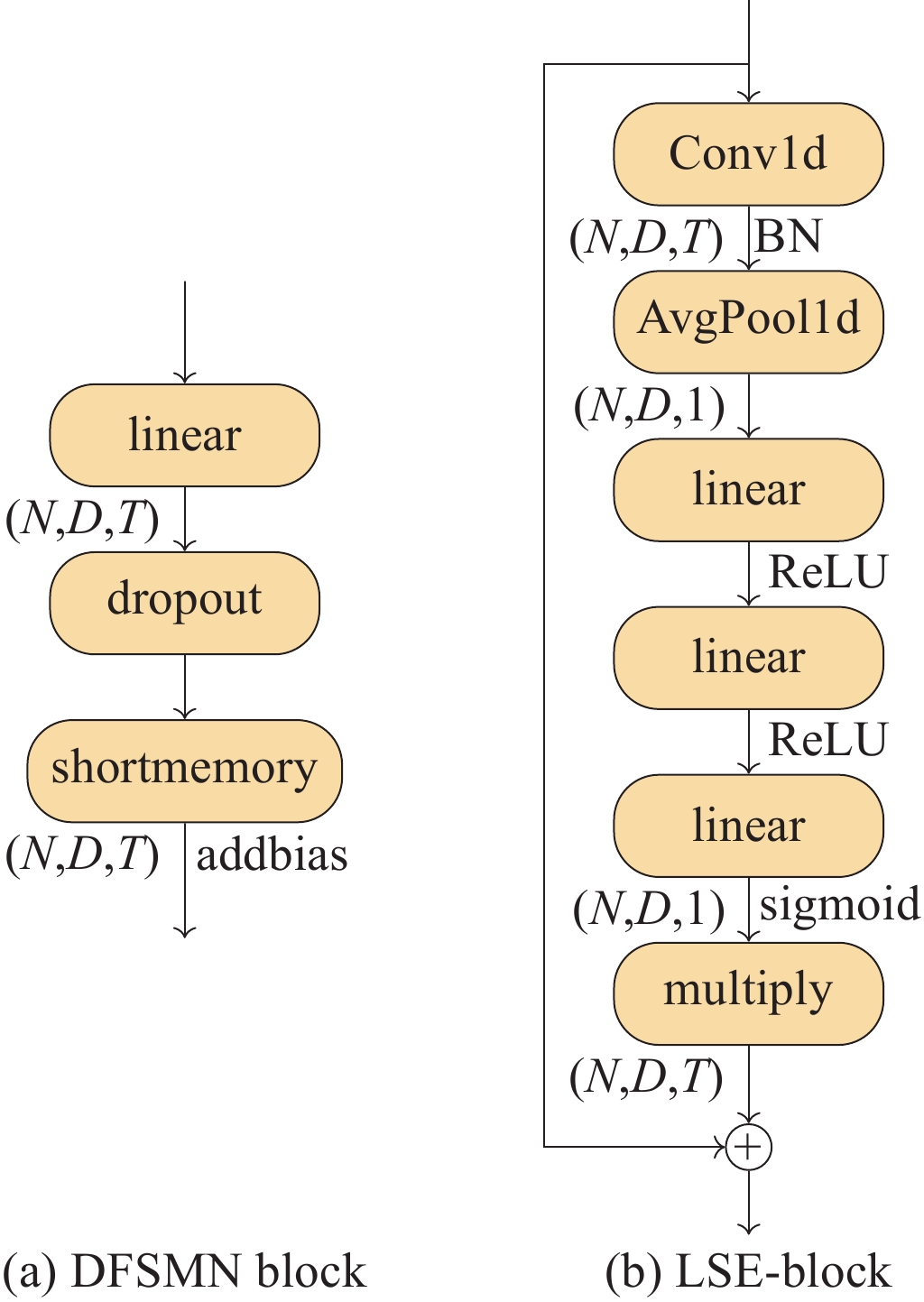
model DFSMN×3 DFSMN×5 LSE-Block TCP EER/% MinDCF 1.25 G 500 M 1.25 G 500 M ELEC-TDNN
(this work)√ √ √ 6.80 0.53 0.1421 0.0624 √ √ √ 5.23 0.53 0.1309 0.0448 √ √ 8.90 0.35 0.1361 0.0178 √ √ 7.85 2.32 0.1361 0.2339 NeXt-TDNN 8.38 1.60 0.1309 0.0689 ECAPA-TDNN 5.76 0.53 0.1257 0.0629  下载: 导出CSV
下载: 导出CSV
-
[1] 秦鑫, 黄洁, 王建涛, 等. 基于无意调相特性的雷达辐射源个体识别[J]. 通信学报, 2020, 41(5): 104-111Qin Xin, Huang Jie, Wang Jiantao, et al. Radar emitter identification based on unintentional phase modulation on pulse characteristic[J]. Journal on Communications, 2020, 41(5): 104-111 [2] 刘壮, 李陆, 杨轩. 计算机电磁指纹提取和识别技术研究[J]. 计算机时代, 2022(5): 19-24Liu Zhuang, Li Lu, Yang Xuan. Research on electromagnetic fingerprint extraction and identification technology of computer[J]. Computer Era, 2022(5): 19-24 [3] Chen Yang, Liu Jinming, Mao Jian. Blind source separation of electromagnetic signals based on deep focusing U-Net[J]. Journal of Intelligent & Fuzzy Systems, 2023, 45(5): 9157-9167. [4] Chen Yang, Liu Jinming, Mao Jian, et al. Blind source separation of electromagnetic signals based on Swish-Tasnet[J]. Circuits, Systems, and Signal Processing, 2024, 43(10): 6620-6636. doi: 10.1007/s00034-024-02653-x [5] Chen Yang, Liu Jinming, Mao Jian. Blind source separation of electromagnetic signals based on one-dimensional U-Net[C]//Proceedings of the 2022 6th International Conference on Electronic Information Technology and Computer Engineering. 2023: 1597-1602. [6] Liu Taikang, Li Yongmei. Electromagnetic information leakage and countermeasure technique[M]. Singapore: Springer, 2019. [7] 刘波, 徐艳云, 黄伟庆, 等. 基于电磁指纹特征的USB行为识别方法研究[J]. 信息安全学报Liu Bo, Xu Yanyun, Huang Weiqing, et al. Study on USB behavior recognition method based on electromagnetic fingerprint features[J]. Journal of Cyber Security [8] 俞佳宝, 胡爱群, 朱长明, 等. 无线通信设备的射频指纹提取与识别方法[J]. 密码学报, 2016, 3(5): 433-446Yu Jiabao, Hu Aiqun, Zhu Changming, et al. RF fingerprinting extraction and identification of wireless communication devices[J]. Journal of Cryptologic Research, 2016, 3(5): 433-446 [9] Ogli F K I. Study of the spectrum of side electromagnetic radiations of video interface DVI[C]//Proceedings of 2021 International Conference on Information Science and Communications Technologies. 2021: 1-3. [10] Soltanieh N, Norouzi Y, Yang Yang, et al. A review of radio frequency fingerprinting techniques[J]. IEEE Journal of Radio Frequency Identification, 2020, 4(3): 222-233. doi: 10.1109/JRFID.2020.2968369 [11] Guo Shanzeng, White R E, Low M. A comparison study of radar emitter identification based on signal transients[C]//Proceedings of 2018 IEEE Radar Conference. 2018: 286-290. [12] Yang K, Kang J, Jang J, et al. Multimodal sparse representation-based classification scheme for RF fingerprinting[J]. IEEE Communications Letters, 2019, 23(5): 867-870. doi: 10.1109/LCOMM.2019.2905205 [13] Rajendran S, Sun Zhi, Lin Feng, et al. Injecting reliable radio frequency fingerprints using metasurface for the internet of things[J]. IEEE Transactions on Information Forensics and Security, 2021, 16: 1896-1911. doi: 10.1109/TIFS.2020.3045318 [14] Xu Jinlong, Wei Dong, Huang Weiqing. Polarization fingerprint: a novel physical-layer authentication in wireless IoT[C]//Proceedings of 2022 IEEE 23rd International Symposium on a World of Wireless, Mobile and Multimedia Networks. 2022: 434-443. [15] Senoussaoui M, Kenny P, Dehak N, et al. An i-vector extractor suitable for speaker recognition with both microphone and telephone speech[C]//Proceedings of Odyssey 2010: The Speaker and Language Recognition Workshop. 2010. [16] Dehak N, Kenny P J, Dehak R, et al. Front-end factor analysis for speaker verification[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4): 788-798. doi: 10.1109/TASL.2010.2064307 [17] Hinton G, Deng Li, Yu Dong, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97. doi: 10.1109/MSP.2012.2205597 [18] Guo Jiacheng, Sun Huiming, Qin Minghai, et al. A min-max optimization framework for multi-task deep neural network compression[C]//Proceedings of 2024 IEEE International Symposium on Circuits and Systems. 2024: 1-5. [19] Snyder D, Garcia-Romero D, Sell G, et al. X-vectors: robust DNN embeddings for speaker recognition[C]//Proceedings of 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. 2018: 5329-5333. [20] Snyder D, Garcia-Romero D, Sell G, et al. Speaker recognition for multi-speaker conversations using X-vectors[C]//Proceedings of 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. 2019: 5796-5800. [21] Desplanques B, Thienpondt J, Demuynck K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification[C]//Proceedings of the 21st Annual Conference of the International Speech Communication Association. 2020: 3830-3834. [22] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778. [23] Wang Rui, Wei Zhihua, Duan Haoran, et al. EfficientTDNN: efficient architecture search for speaker recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2267-2279. doi: 10.1109/TASLP.2022.3182856 [24] Heo H J, Shin U H, Lee R, et al. NeXt-TDNN: modernizing multi-scale temporal convolution backbone for speaker verification[C]//Proceedings of 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. 2024: 11186-11190. [25] Kingma D P, Ba J. Adam: a method for stochastic optimization[C]//Proceedings of the 3rd International Conference on Learning Representations. 2015. [26] Zhang Shiliang, Lei Ming, Yan Zhijie, et al. Deep-FSMN for large vocabulary continuous speech recognition[C]//Proceedings of 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. 2018: 5869-5873. [27] Bai Shaojie, Kolter J Z, Koltun V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[DB/OL]. arXiv preprint arXiv: 1803.01271, 2018. [28] Hu Jie, Shen Li, Sun Gang. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2018: 7132-7141. [29] Okabe K, Koshinaka T, Shinoda K. Attentive statistics pooling for deep speaker embedding[C]//Proceedings of the 19th Annual Conference of the International Speech Communication Association. 2018: 2252-2256. -
 点击查看大图
点击查看大图
图(4) / 表(1)
计量
- 文章访问数: 58
- HTML全文浏览量: 38
- PDF下载量: 3
- 被引次数: 0
