

Preliminary implementation of event-based GPU-acceleration in NECP-MCX
-
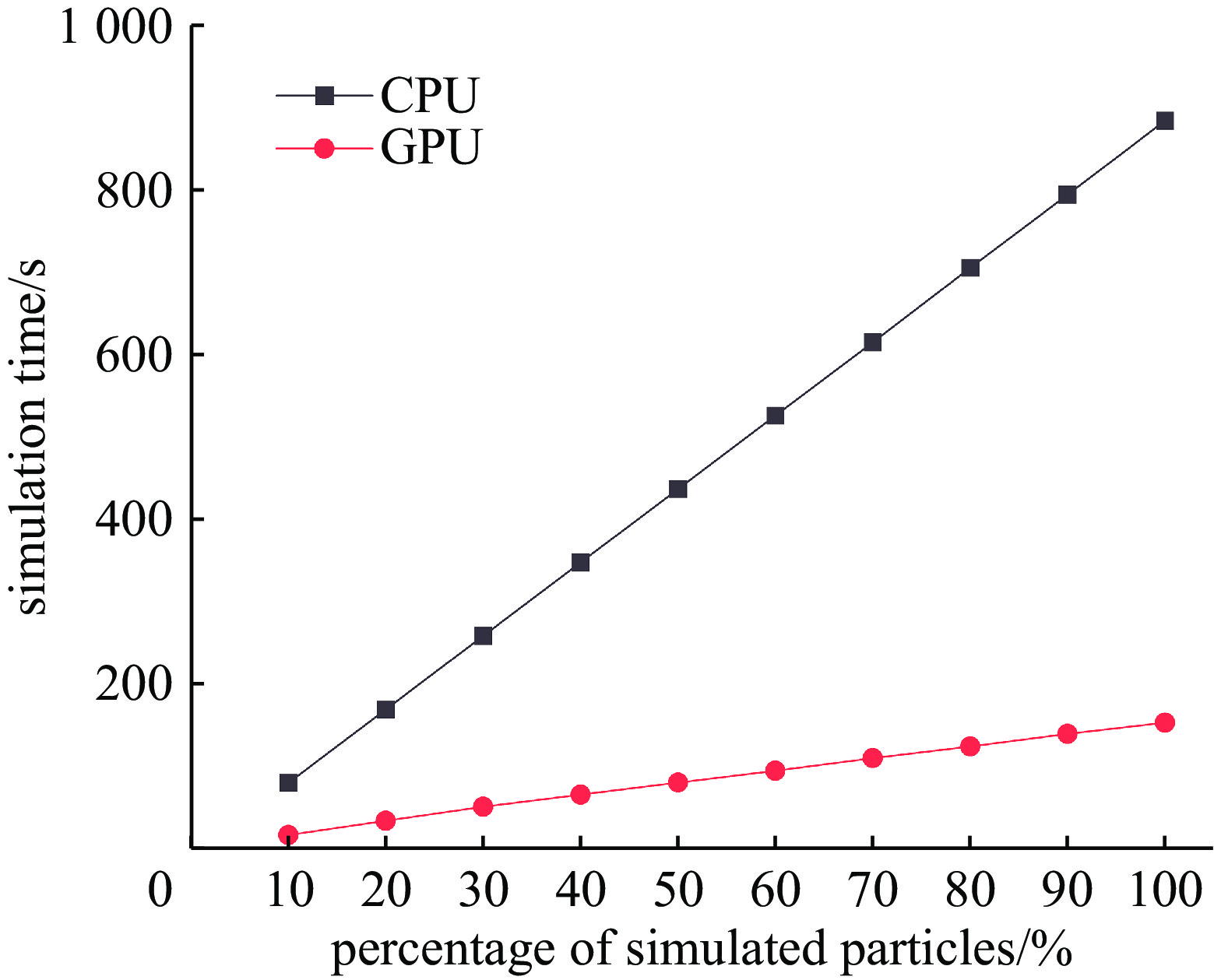
摘要: 蒙特卡罗方法进行辐射屏蔽模拟时效率低下,使用特定的降方差技巧是加速辐射屏蔽模拟的方法之一,另一种更通用的方法是使用大规模并行技术从硬件方面提升模拟速度。目前由于人工智能技术发展引起的对算力的庞大需求,各大超算平台对大规模GPU并行架构的支持稳步提升,为了适应目前和未来超算平台的GPU并行架构,开发适用于GPU平台的蒙特卡罗输运算法很有必要。本文旨在利用GPU并行加速NECP-MCX蒙特卡罗粒子输运程序的固定源计算,进而加速辐射屏蔽输运模拟。本文分析了GPU事件并行算法在固定源计算模式下的特性,在NECP-MCX程序中初步部署了GPU事件并行算法,基于简单固定源问题进行了测试分析,结果表明,最大同时模拟事件数与模拟速度正相关,对粒子信息排序能够加速28%,GPU并行速度为单核CPU运行速度的25倍。初步的GPU并行加速展现出了显著的加速潜力,然而,若要充分挖掘其能力并优化整体性能,需要进一步的研究。Abstract:
Background When using the Monte Carlo method for radiation shielding simulations, the efficiency is low. Employing specific variance reduction techniques is one of the methods to accelerate radiation shielding simulations, while another more universal approach is to use large-scale parallel technology to enhance the simulation speed from the hardware aspect. At present, due to the enormous demand for computing power triggered by the development of artificial intelligence technology, major supercomputing platforms have steadily improved their support for large-scale GPU parallel architectures. To adapt to the current and future GPU parallel architectures of supercomputing platforms, it is necessary to develop Monte Carlo transport algorithms suitable for GPU platforms.Purpose This paper aims to accelerate fixed-source calculation of the NECP-MCX Monte Carlo particle transport code by utilizing GPU parallel, thereby enhancing the efficiency of radiation shielding transport simulations.Method This paper analyzes the characteristics of the GPU event-based parallel algorithm under the fixed-source mode. The GPU event-based parallel algorithm has been preliminarily implemented within the NECP-MCX code and was tested and analyzed using a simple fixed-source problem.Results The results show that the maximum number of simultaneous simulated events is positively correlated with the simulation speed. Sorting particle information can accelerate the simulation by 28%, and the GPU parallel implementation is 25 times faster than the single-core CPU implementation.Conclusions The initial implementation shows significant potential for acceleration; however, further research is essential to fully exploit its capabilities and optimize performance.-
Key words:
- Monte Carlo /
- GPU /
- event-based parallel /
- radiation shielding /
- NECP-MCX
-
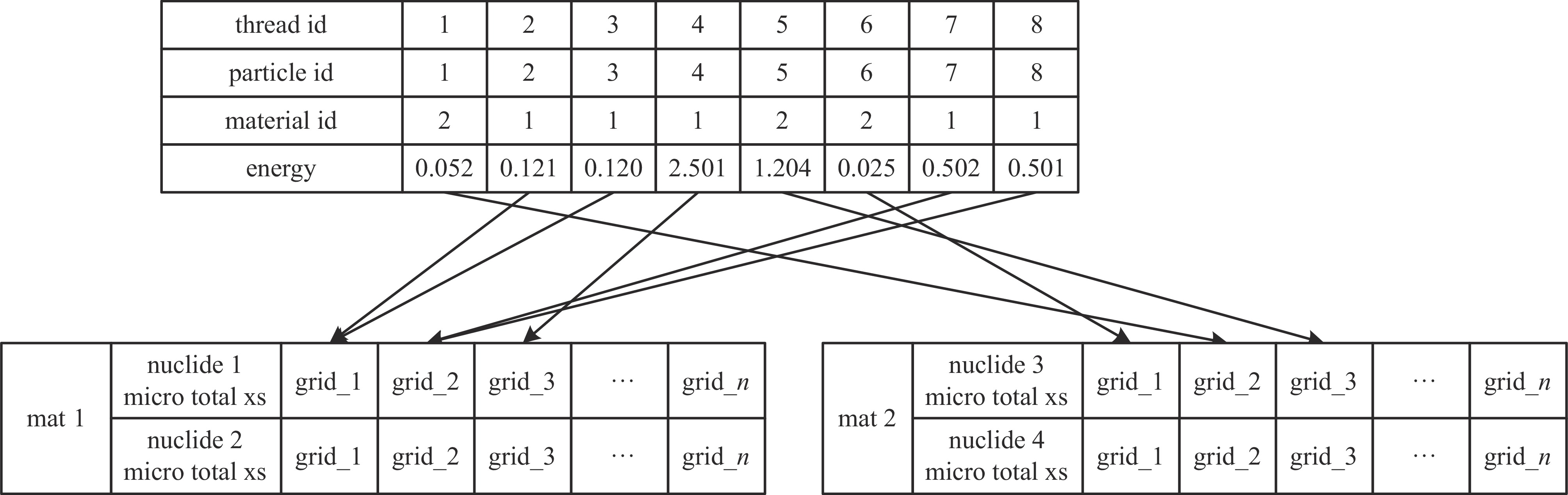
图 2 无粒子信息排序的GPU线程访存
Figure 2. memory access of GPU threads without particle information sorting
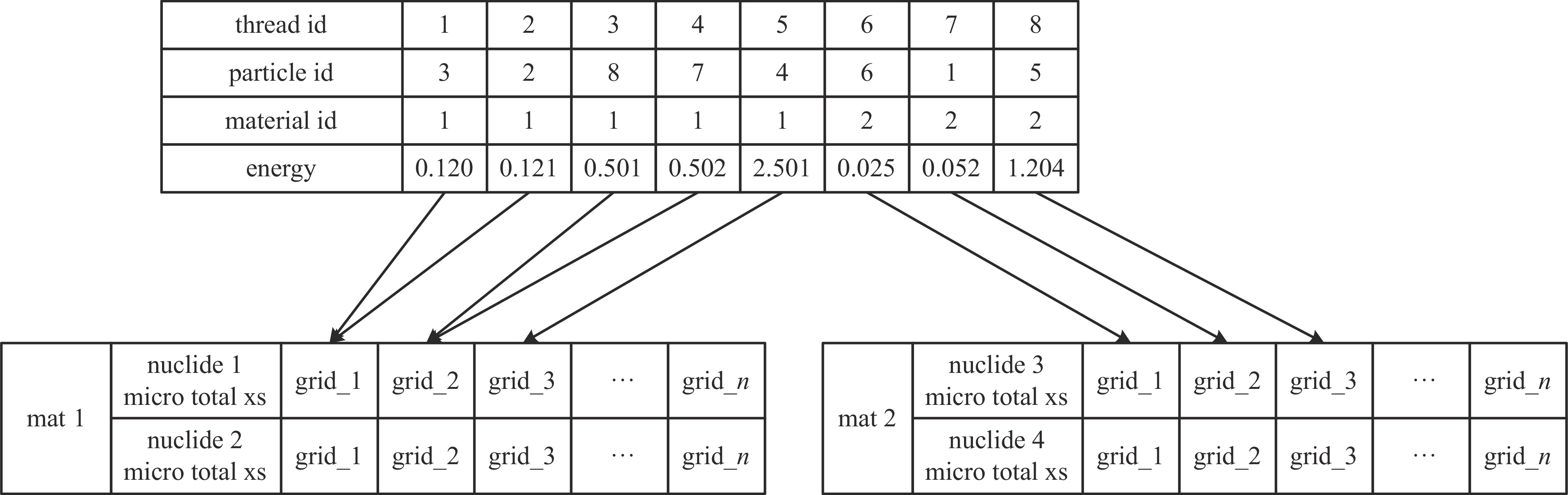
图 3 有粒子信息排序的GPU线程访存
Figure 3. memory access of GPU threads with particle information sorting
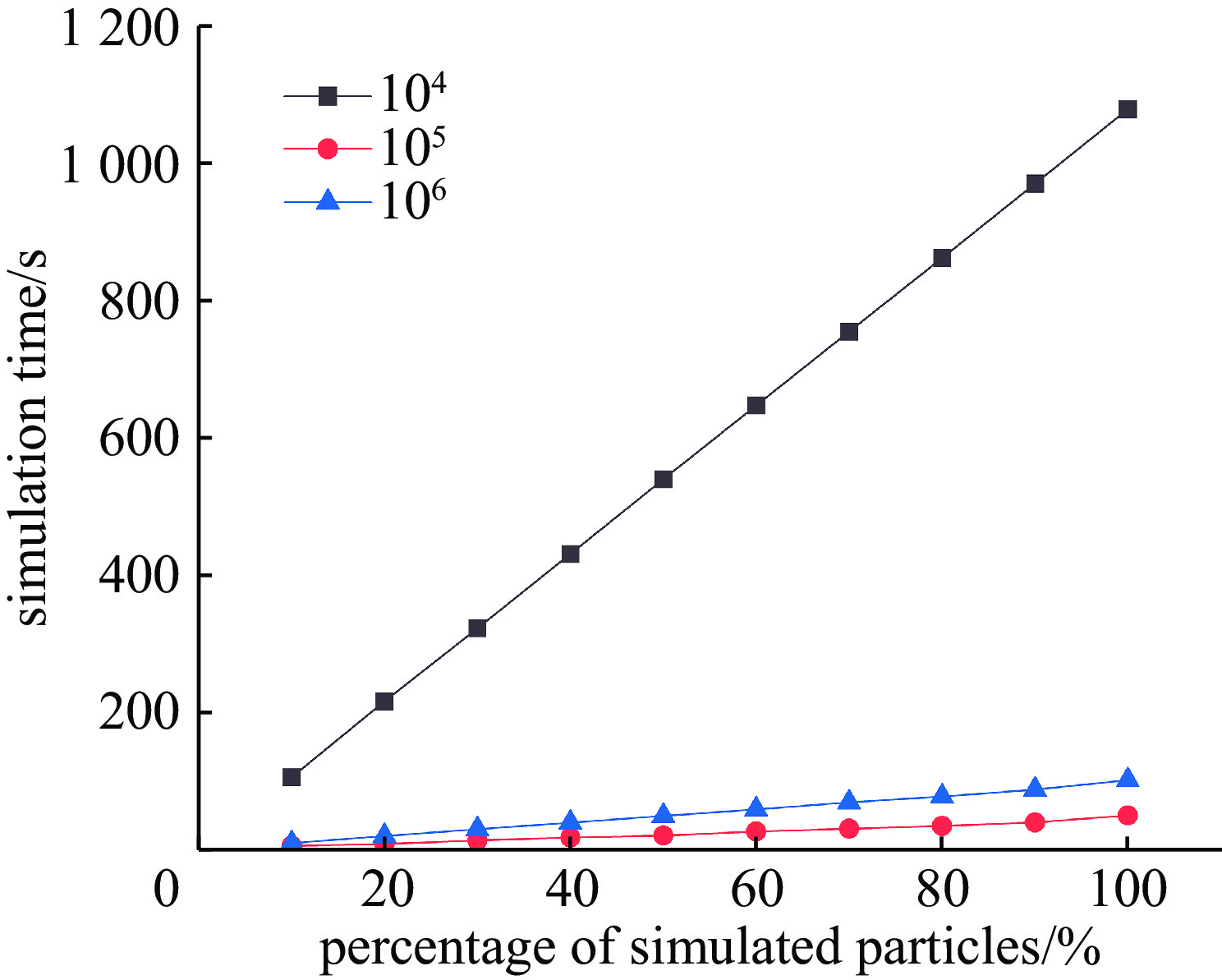
图 7 不同最大同时模拟事件下的运行耗时
Figure 7. computation time with different maximum event queue sizes
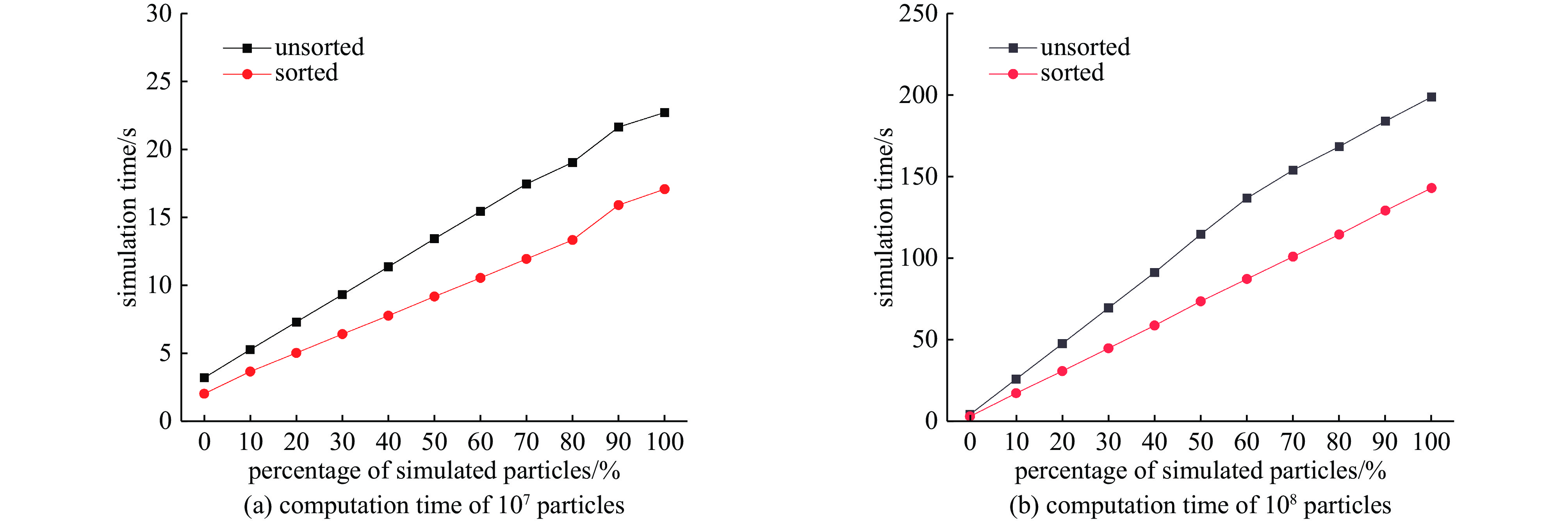
图 8 排序与不排序的计算耗时对比
Figure 8. comparison of computation time between sorting and non-sorting
-
[1] Bergmann R. The development of WARP – a framework for continuous energy Monte Carlo neutron transport in general 3D geometries on GPUs[D]. Berkeley: University of California, 2014. [2] Hamilton S P, Evans T M. Continuous-energy Monte Carlo neutron transport on GPUs in the Shift code[J]. Annals of Nuclear Energy, 2019, 128: 236-247. doi: 10.1016/j.anucene.2019.01.012 [3] Ridley G. GPU-oriented algorithms for continuous energy Monte Carlo neutron transport[D]. Cambridge: Massachusetts Institute of Technology, 2024. [4] Choi N, Kim K M, Joo H G. Initial Development of PRAGMA - A GPU-Based Continuous Energy Monte Carlo Code for Practical Applications[C]. The Korean Nuclear Society Autumn Meeting. Goyang, Korea, October 24-25, 2019. [5] Ali M R, Aygul M S, Lee D. GPU-optimized Monte Carlo code development – preliminary results[C]//Proceedings of the Reactor Physics Asia 2023 (RPHA2023) Conference. 2023. [6] 任禹铄, 李泽光, 彭立坤, 等. 蒙卡计数器与裂变库高效GPU并行方法研究[C]//第十七届全国蒙特卡罗方法及其应用学术交流会. 2025Ren Yushuo, Li Zeguang, Peng Likun, et al. Research on high-efficiency GPU parallelization methods for Monte Carlo tallies and fission banks[C]//Proceedings of the 17th National Academic Conference on Monte Carlo Methods and Their Applications. 2025 [7] Hamilton S P, Evans T M, Royston K E, et al. Domain decomposition in the GPU-accelerated Shift Monte Carlo code[J]. Annals of Nuclear Energy, 2022, 166: 108687. doi: 10.1016/j.anucene.2021.108687 [8] Kim K M, Choi N, Lee H G, et al. Practical methods for GPU-based whole-core Monte Carlo depletion calculation[J]. Nuclear Engineering and Technology, 2023, 55(7): 2516-2533. doi: 10.1016/j.net.2023.04.021 [9] Royston K E, Evans T M, Hamilton S P, et al. Weight window variance reduction on GPUs in the Shift Monte Carlo Code[C]//Proceedings of the International Conference on Mathematics and Computational Methods Applied to Nuclear Science and Engineering. 2023. [10] Evans T M, Royston K E, Hamilton S P, et al. Automated hybrid variance reduction on advanced architectures in the Shift Monte Carlo Code[J]. Nuclear Science and Engineering, 2026, 200(2): 444-470. doi: 10.1080/00295639.2025.2484511 [11] He Qingming, Zheng Qi, Li Jie, et al. NECP-MCX: a hybrid Monte-Carlo-deterministic particle-transport code for the simulation of deep-penetration problems[J]. Annals of Nuclear Energy, 2021, 151: 107978. doi: 10.1016/j.anucene.2020.107978 [12] Wagner J C, Peplow D E, Mosher S W. FW-CADIS method for global and regional variance reduction of Monte Carlo radiation transport calculations[J]. Nuclear Science and Engineering, 2014, 176(1): 37-57. doi: 10.13182/NSE12-33 [13] He Qingming, Huang Zhanpeng, Cao Liangzhi, et al. The methods of CADIS-NEE and CADIS-DXTRAN in NECP-MCX and their applications[J]. Nuclear Engineering and Technology, 2024, 56(7): 2748-2755. doi: 10.1016/j.net.2024.02.036 [14] Huang Zhanpeng, Jo Y, He Qingming, et al. Performance improvement of weight window method by incorporating DXTRAN[J]. Nuclear Science and Engineering, 2025, 199(9): 1391-1405. doi: 10.1080/00295639.2024.2438570 [15] Brown F B, Martin W R. Monte Carlo methods for radiation transport analysis on vector computers[J]. Progress in Nuclear Energy, 1984, 14(3): 269-299. doi: 10.1016/0149-1970(84)90024-6 [16] Martin W R, Brown F B. Status of vectorized Monte Carlo for particle transport analysis[J]. The International Journal of Supercomputing Applications, 1987, 1(2): 11-32. doi: 10.1177/109434208700100203 -
 下载:
下载:
 点击查看大图
点击查看大图
计量
- 文章访问数: 15
- HTML全文浏览量: 7
- PDF下载量: 0
- 被引次数: 0
